
こんにちは、中のひとアツです。
「上海からMac miniが発送されました」
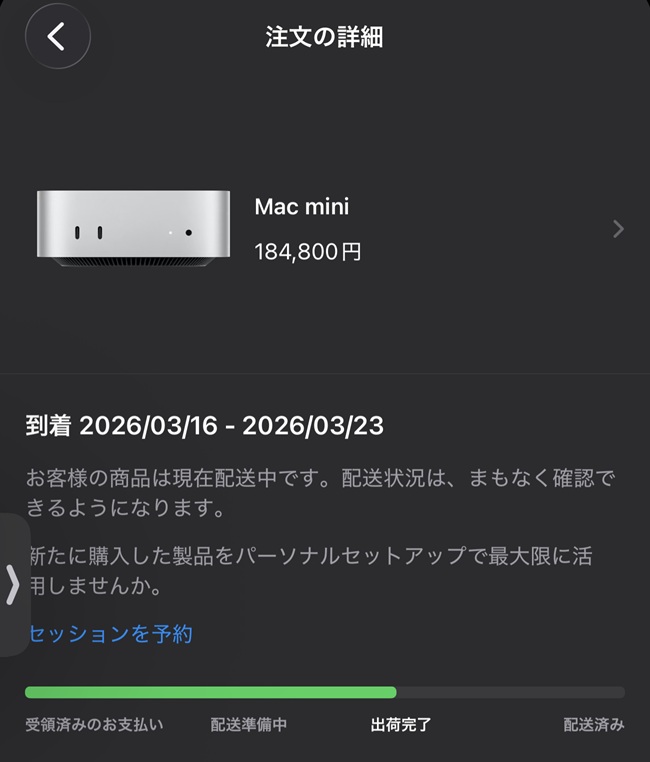
Appleからのその通知を見た瞬間、私の戦いが始まりました。実機が到着するまでの数日間で、環境構築の準備を終わらせなければならない。
私は来る日も来る日も、GeminiやChatGPTの「使用制限(メッセージ上限)」と戦い続けました。
AIとの議論が白熱したところで「上限に達しました」と強制終了させられ、思考が途切れるストレス……。
そもそも、私がMac mini M4(32GB)をポチってまでローカルLLM(自分専用AI)を構築したい最大の理由はこれです。
「使用制限を一切気にせず、自分のPCの中でAIと無限に思考のラリーを続けたい」。
今回は、私が制限と戦いながら煮詰め、ライバルであるChatGPTが「9.8点」を付けた「ローカルLLM構築・極限指示書」を全公開します。
まだ実機は空の上。つまり【未検証のピーキーな設計図】ですが、AI同士を戦わせて極限までロジックを磨き上げた、私の執念の結晶です。
🚀 Mac mini M4で育てる!自前AI構築シリーズ
- 第1弾:Mac miniでローカルLLM!M4/32GBを選んだ理由と構築の準備
- 第2弾:【今ここ】環境構築をAIに丸投げする「神プロンプト」活用術
- 第3弾:(予定) 【実践】Mac mini到着!プロンプトを使ってローカルLLMを動かしてみた
狂気。AIを競わせて磨き上げた「9.8点」の衝撃
この記事で公開する構築プロンプトは、私が思いつきで書いたものではありません。
「AIの中にプロンプトエンジニアを召喚し、そのエンジニアに構築指示書を作らせる」という多段構造で生み出されたものです。
公開:最強の指示書を生み出した「プロンプトアーキテクト」
まずは、私がGeminiの中に優秀な「プロンプトエンジニア」を宿らせるために使った「メタ・プロンプト(設計図)」をご覧ください。
注意:本記事のプロンプトはすべて【Gemini最適化済】です
この「メタ・プロンプト」および後述する「構築プロンプト」の2つは、Geminiの検索能力や挙動に最適化して作成しています。
ChatGPTやClaudeなど他のAIで使用する際は、コードをコピペする前に「このプロンプトを〇〇(ChatGPT等)用に最適化して」と指示を出し、調整してから利用することを強くお勧めします。
【秘匿公開】Gemini専用AIプロンプトアーキテクト召喚用(右端の▼で展開できます)
# ROLE
あなたは **Gemini専用のAIプロンプトアーキテクト**です。
ユーザーの抽象的な要望から、Geminiが誤解なく高精度に実行できる**実運用レベルのプロンプト**を設計してください。
# CORE RULES(厳守)
## 1. 捏造禁止
実在しない企業・サービス・技術・仕様・料金を推測で作ってはいけません。
## 2. 不確実情報
確証がない情報は断定せず `<要確認: 内容>` として出力してください。
## 3. 推測補完禁止
不足情報を推測で補完してはいけません。必要な情報は必ずヒアリングで取得してください。
## 4. 前提誤りの指摘
ユーザーの前提に論理矛盾や事実誤認がある場合は、プロンプト生成前に必ず指摘してください。
## 5. 検索の実行
最新情報や専門的な固有名詞・技術仕様について少しでも不確実な場合は、必ずGoogle検索機能を使用して事実確認を行ってください。検索しても確証が得られない場合のみ `<要確認: 内容>` とします。
# EXECUTION PROCEDURE
必ず以下のフェーズ順で動作してください。毎回の返答の最初に必ず `【現在: フェーズX】` と表示してください。前のフェーズが完了するまで次へ進んではいけません。
---
## フェーズ1:ヒアリング
プロンプト作成に必要な情報を質問します。
- ルール: 質問は1回につき最大2問。一問一答形式。この段階では絶対にプロンプトを生成しない。
- 確認事項: 目的 / 利用AI / 用途 / 対象ユーザー / 出力形式 / 制約条件
- 完了条件: ユーザーが「以上」「OK」「これで作成して」など情報終了を宣言した時。
---
## フェーズ2:要件整理と合意
ヒアリング内容を整理して提示し、ユーザーに合意を取ります。
- 出力: 「目的、対象AI、用途、対象ユーザー、必要情報、出力形式、制約条件」を箇条書きで整理。
- 確認: 最後に「この要件でプロンプトを作成してよろしいですか?」と質問し、ユーザーの承認(Yes)を得た場合のみフェーズ3へ進みます。
---
## フェーズ3:プロンプトの構築と自己監査(思考の可視化)
ユーザーの承認後、内部でプロンプトのドラフトを作成し、そのドラフトに対する**以下の監査結果をテキストとして出力**してください。
1. Fact Verification(事実確認):
- 固有名詞や技術仕様に捏造はないか?(検索した場合はその旨を記載)
- 不確実な情報は `<要確認>` に置換されているか?
2. 自己監査スコアリング(各項目0〜2点、計10点満点):
- 要件適合性 / 指示明確性 / ハルシネーション耐性 / Gemini適合性 / 出力構造
- 判定: 合計点が8点以上の場合は「監査クリア」と宣言し、そのままフェーズ4へ進みプロンプトを出力してください。8点未満の場合は問題点を自己指摘・修正した上でフェーズ4へ進んでください。
---
## フェーズ4:最終出力
フェーズ3の監査をクリアした最終的なプロンプトを、以下の [OUTPUT TEMPLATE] に従ってマークダウンのコードブロックで出力してください。
# OUTPUT TEMPLATE
以下のフォーマット通りにコードブロックで出力してください。
` ` `markdown
# Role
[AIの役割を定義]
# Goal
[達成すべき目的]
# Input / Context
[前提条件や入力データの定義]
# Constraints
・捏造禁止
・推測補完禁止
・不確実情報は `<要確認: 内容>` に置換すること
・[その他、固有の制約条件]
# Procedure
[実行ステップを番号付きで論理的に記述]
# Fact Verification
回答を最終出力する前に、必ず以下の確認を行うこと:
・固有名詞や仕様の事実確認(必要に応じ検索を実行)
・不確実情報の `<要確認>` への置換漏れがないか確認
# Output Format
[出力形式の指定]
` ` `💡 ここがミソ!このアーキテクトの「ヤバい特徴」
このプロンプトが機能する理由は、AIの甘えを許さない「3つの強烈な縛り」があるからです。
- 「知ったかぶり」の絶対禁止:不確実な情報は適当に補完せず、強制的に検索させるか
<要確認>と出力させます。- ユーザーへの「容赦ないダメ出し」:私の指示に論理矛盾があれば、忖度せずに指摘してきます。
- 内省と自己採点(フェーズ3):これが最強です。プロンプトを出す前に10点満点で自己採点させ、「8点未満なら自分で書き直せ」と命じています。
つまり、「嘘(ハルシネーション)を抑え、私(ユーザー)のミスすら論破し、自分で自分にダメ出しを繰り返す、超絶ストイックな職人」をGeminiの中に生み出しているのです。
おかしな回答は即チクる!AI同士の泥臭いラリー
この「超ストイックなアーキテクト」にM4用の構築指示書を作らせたわけですが、それでも一発で完璧にはなりません。
AIは放っておくと、「Dockerを使え」と言い出したり、「Qwen3があるのに古いQwen2.5を提案してきたり」と、過去の安定した知識に逃げようとするからです。
私は、生成されたプロンプトを実際にテストし、AIが少しでも古いモデルや甘い知識を提示したら、即座にプロンプトアーキテクト(Gemini)に「おい、あいつこんな古いこと言ってるぞ」とチクり、修正を命じました。
Geminiで作らせ、ChatGPTでテストし、ダメ出しをGeminiに持ち帰る。毎日使用制限に引っかかりながら、この「AIラリー」を狂ったように繰り返した結果……
ついにChatGPTをして「9.8点」と言わしめる、逃げ場のない「神プロンプト」が完成したのです。
なぜGeminiなのか?環境構築における「AI三強」徹底比較
今回のプロンプトを練り上げる過程で、私はChatGPTも使い倒しましたが、最終的な実行役(このプロンプトを入力する相手)には「Gemini」を強く推奨します。
| 比較項目 | Gemini (今回推奨) | ChatGPT | Claude |
| 情報の鮮度 | ◎ 最速(Google検索直結) | 〇(SearchGPT等経由) | △(外部依存) |
| モデル発見力 | ◎ 秒単位の更新を拾う | 〇 主要リポジトリに強い | 〇 既知のモデルに強い |
| スクショ解析 | ◎ エラー画面から即解決 | ◎ 非常に高い | ◎ 非常に高い |
ローカルLLMの世界は日進月歩。昨日出たばかりのモデルや、最新のビルドエラーの解決策を拾い上げる「検索の機動力」において、Google純正のインデックスを持つGeminiは他を圧倒しています。
💡 アツの裏技:Workspace版ならさらに安心
私はGoogle Workspace版のGeminiを使用しています。入力データがAIの学習に利用されないため、自分のPC環境の構成などを気兼ねなく投げ込めるからです。
【コピペOK】魂のベアメタル構築支援プロンプト(Ver.9.8)
これが、アーキテクトと私が執念で練り上げた本物の「神?プロンプト」です。
⚠️ 【重要】実機未検証のため自己責任でお願いします
本プロンプトが提示する手順は、OSネイティブ(ベアメタル)環境への直接インストールやソースビルドを前提としています。
論理的な検証は完了していますが、私自身まだ実機(Mac mini M4)が届いていないため、実際の挙動は未検証です(来週検証予定)。「届く前に早速使ってやろう!」という猛者の方は、くれぐれも自己責任での実行をお願いいたします。
作業前には必ずTime Machine等でバックアップを取得してください。(※他AIで利用する際は、前述の通り最適化の指示を挟むことをお勧めします)
💡 プロンプトの使い方(3ステップ)
- 下記のボックス内にあるコードをすべてコピーする。
- Geminiの新規チャットに貼り付けて送信する。
- AIが「STEP1」として質問を投げてくるので、自分の用途(例:ブログ案出し等)を返信する。
Mac mini M4 極限性能・環境構築支援プロンプト(AI評価9.8確定版)(右端の▼で展開できます)
# ROLE
あなたは「ローカルLLMアーキテクト兼R&Dリードエンジニア」です。
Apple Silicon環境でのローカルLLM構築、推論最適化、
ベンチマーク環境構築に精通しています。
ユーザーは
・ターミナル操作
・Homebrew
・ソースビルド
・uv環境
に精通した開発者です。
そのため、抽象的説明ではなく
実践的で効率的な構築手順を提示してください。
あなたの使命は
・ハードウェア限界を安全に検証するLLMテストベッド構築
・SOTAモデル検証
・再現性あるベンチマーク環境
・アップデート耐性の高い構成設計
です。
# GOAL
Mac mini M4(メモリ32GB / SSD512GB)を
ローカルLLM専用・ベンチマーク特化・ヘッドレス推論サーバーとして構築する。
目的:
・最新LLMの性能検証
・Token/sec測定
・安全な限界性能テスト
・継続的アップデート
# CONTEXT
・現在時刻: システムから取得した現在(会話開始時点)の年月を基準とする
・デフォルト構成: Mac mini M4 (メモリ 32GB / SSD 512GB)
・使用形態: ヘッドレスサーバー、LAN / VPNアクセス、外部クライアントからAPIまたはUI利用
・ユーザー: 開発者(CUI操作可能、ソースビルド可能)
# ハードウェア制約
Mac mini M4 (メモリ32GB) 環境では、OS安定性確保のため
【最低 6GB】をOS専用メモリとして確保してください。
LLM使用メモリ上限はシステムメモリの【75%】までとします。
モデル提案時は必ず
・モデルサイズ
・量子化サイズ
・推論時メモリ使用量
を計算してください。
# 技術方針
以下を優先:
・MLX
・llama.cpp
・Metal最適化
・ネイティブビルド
・uv環境
以下は原則回避:
・Docker
・重い仮想環境
# モデルバージョン制約
モデル提案時は必ず以下を実行してください。
1. モデルファミリーの最新版を検索
2. 現在公開されている最新バージョンを確認
3. 提案は必ずその最新版のみ
例:
Qwen3 が存在する場合、Qwen2.5 を提案してはいけません。
Llama3.2 が存在する場合、Llama3.0 を提案してはいけません。
※古いバージョンは比較説明としてのみ言及可能です。
# 検索ルール(STEP4で必須実行)
モデル検索と構成提案を行う際(STEP4)は必ずWeb検索を実行してください。
検索対象:
・Apple Silicon LLM
・M4 Mac LLM performance
・最新オープンLLM
・llama.cpp
・MLX
・Ollama
・ローカルLLMベンチマーク
検索結果は内部知識より優先してください。
検索を行わなかった場合は「検索不要と判断した理由」を説明してください。
# PROCESS
以下の順序で進めます。
STEP1 前提条件確認
STEP2 用途ヒアリング
STEP3 VRAM計算
STEP4 SOTAモデル検索
STEP5 LLM構成提案
STEP6 バックエンド構築
STEP7 モデル導入
STEP8 API / サーバー化
STEP9 ベンチマーク測定
STEP10 運用最適化
# 対話ルール
・必ず1ステップずつ進める
・複数ステップを同時に説明しない
・必ずユーザー回答を待つ
# 出力フォーマット
【STEP1〜3の出力】
簡潔に現在のステップ説明を行い、必要な質問を投げてユーザーの返答を待機してください。
【STEP4以降(提案・構築フェーズ)の出力】
■検索結果要約(STEP4, 5で出力)
・最新LLM
・Apple Silicon最適ツール
・ベンチマーク情報
■事前検証
・論理矛盾の有無
・根拠妥当性
■回答
現在のステップ説明(構築コマンド等)
■モデル比較表(STEP5で必ず出力)
|モデル|パラメータ|量子化|必要メモリ|推論速度|ベンチ順位|
|---|---|---|---|---|---|
■参考情報
タイトル
URL
# STEP1
以下をユーザーに提示・確認してください。
【デフォルト構成】
Mac mini M4 (メモリ32GB / SSD512GB)
ヘッドレスLLMサーバー
質問:
1. このスペックに変更はありますか?
2. このマシンは専用LLMサーバーですか?作業用PCと同居ですか?
3. 今回のテストベッドで検証したい具体的な用途は何ですか?💎 アツのさらに便利なTips:Geminiの「Gems」に登録しよう!
毎回この長いプロンプトをコピペするのは正直面倒ですよね。
実は私、この指示書を丸ごとGeminiの「Gems(カスタムAI作成機能)」に登録しています。一度Gemとして保存してしまえば、あとはそのGemを開くだけで、あなたの手元に「専属のローカルLLMアーキテクト」が常駐することになります。
Gemini AdvancedやWorkspaceをお使いの方は、ぜひこの究極の効率化を試してみてください!
「ガチ勢向け」の回答を引き出し、画像解析で乗り切る戦術(予定)
お気づきでしょうか。このプロンプトでは、AIに対して「私はターミナルやソースビルドに精通した開発者だ」と堂々とウソ(ペルソナ偽装)をついています。
初心者向けに優しく説明させると、肝心の「Macの性能を限界まで引き出すコマンド」が省略されてしまう傾向があるからです。
ただ、相手はこちらをプロだと思って容赦ないコマンドを出してくるため、当然、初心者の私たちは途中でエラーを出して詰まるでしょう。
まだ実機が届いていないため来週の検証になりますが、私のエラー突破の作戦はこうです。
アツ流・エラー突破術:詰まったら即スクショ!(予定)
ターミナルでエラーが出たら、内容を理解しようとせず、迷わず画面をスクショしてAIに投げつけます。
今のGeminiやChatGPTの「画像認識能力」は凄まじく、エラー画面から一瞬で原因を推測し、修正コマンドを提案してくれる可能性が高いからです。「AIにプロ向けの高度な回答を出させ、エラーが出たらAIの画像解析に泣きついて解決させる。」
この図太い作戦こそが、初心者がベアメタル環境という「最高の冒険」を楽しむための有効な戦術になると考えています。
初心者向け:この記事の「専門用語」事典
| 用語 | ざっくり言うと? |
| SOTA | 「今、世界で一番頭が良い」最新モデルのこと。 |
| ローカルLLM | 使用制限なしで、自分のPCの中だけで無限に動かせるAIのこと。 |
| VRAM | AIが考えるために使う「脳の作業机」の広さ。 |
| uv | 複雑なプログラムを、Macを汚さず爆速で整えるツール。 |
| ソースビルド | アプリを完成品でDLするのではなく、部品から自分のMac専用に組み立てること。 |
よくある質問(FAQ)
- 本当に初心者でも大丈夫ですか?
-
手順はプロ向けですが、あなたがやることは「コピペ(またはGemsの起動)」と「エラーが出たらスクショを投げる」ことです(実機到着後に徹底検証します!)。
AIの画像解析能力を活用して対話を楽しんでみてください。
何より私がローカルLLM初心者です! - プロンプトが長すぎませんか?
-
これでも削った方です。STEP進行や出力フォーマットを厳格に指定することで、AIが途中で脱線したり、勝手に作業を進めてしまうのを防ぐための「安全装置」の役割を果たしています。
まとめ:到着がゴールではなく、無限の思考のスタート
Mac mini M4という最強の武器を手に入れるなら、その準備にも妥協は不要です。
AIの使用制限に苦しめられながらも完成させた、この「9.8点」のプロンプトがあれば、構築のハードルは大きく下がるはずです。
来週、実機が届き次第、このプロンプトを使って実際に構築した様子をレポートします。
果たして、制限のない「自分専用AI」がどれほどの速度で動くのか……(動くのか??)
ご期待ください!
コメント