
こんにちは、中のひとアツです。
前回の第5回では、ついにMac mini(M4)のローカル環境に「llama.cpp」を導入し、AIを動かす土台を完成させました。
今回は、その土台の上で動かす「AIの脳みそ」にあたる部分、LLM(大規模言語モデル)を「Hugging Face」からダウンロードして追加する方法を解説します。
【連載:M4 Mac miniで最強ローカルLLM環境を作る!】
⭐️ [ハブ記事:M4 Mac mini 32GB ローカルLLM環境構築の全貌と手順まとめ]
・ [第1回:Mac miniでローカルLLM!M4/32GBを選んだ理由と構築の準備]
・ [第2回:【評価9.8】AIに構築を丸投げする神プロンプト活用術(※お詫びあり)]
・ [第3回:AIがOllama・OrbStackを捨てた?「ネイティブ + uv」最強構成の理由]
・ [第4回:Mac mini M4 (32GB) 向けLLM選定リスト|限界を攻める最強の布陣]
・ [第5回:M4 Mac mini(32GB)ローカルLLM構築!失敗しないllama.cpp導入実践記](更新)
👉 第6回:llama.cpp用にHugging FaceからLLMモデルをダウンロードする方法(今ココ)
・ [第7回:【拡張編】自前RAG!ローカルLLMにSearXNGをネイティブ構築] (予定)
・ [第8回:インストールしたLLMモデルのベンチマーク(予定)]
🟢 本題の前に:実はSFTP(GUI)でポン置きするのが一番楽です!
具体的な手順に入る前に、一つ大事なことをお伝えしておきます。
モデル(GGUFファイル)の追加や削除は、もちろん普段お使いのクライアントPCのブラウザでダウンロードし、「FileZilla」や「Cyberduck」などのSFTPソフトを使って、Mac miniの該当ディレクトリ(/modelsなど)へマウスで直接ドラッグ&ドロップしていただいて全く問題ありません。不要なファイルの削除も、右クリックで消すだけです。
ぶっちゃけ、そちらの方が視覚的にもわかりやすく、圧倒的に楽です。
 アツ
アツこれから解説する「黒い画面(CUI)でコマンドを打ってダウンロードする手順」は、私の単なる惰性です(笑)。
「わざわざ転送ソフトを開いて手元にダウンロードするのも面倒だし、SSHで入ったついでにコマンド一発で全部済ませちゃおう」という、サボりですね。
ですが、私がわざわざSSH(黒い画面)を使ってダウンロードしているのには、「サボり」以上の明確な理由があります。
なぜSSH(ターミナル)で完結させるのか?
それは、「新しいモデルをフォルダに入れただけではAIは認識してくれず、結局最後にシステム(llama.cpp)を再起動するコマンドを打たなければいけないから」です。
- クライアントPCで何GBもあるファイルをダウンロードする
- SFTPソフトを開いてMac miniへ転送する(ここでまた時間がかかる)
- 結局、ターミナルを開いてMac miniにSSH接続し、再起動コマンドを打つ
この手順を踏むくらいなら、「最初からSSHでMac miniに入り、直接Hugging FaceからMac miniへダウンロードさせ、そのまま再起動コマンドを打つ」という一筆書きのほうが、時間も手間もかからず圧倒的に合理的なのです。
とはいえ、「どうしてもコマンドは怖いな…」という方は、SFTPソフトを使ってGUIでファイルを直接指定のフォルダに放り込んでください!
ただしその場合でも、後述する「Step 3: 新しいモデルを認識させる再起動の儀式」だけは絶対に必要になりますので、そこだけはしっかり読んでくださいね。
失敗しない!Hugging Faceでのモデル(リポジトリ)の選び方
Hugging Faceには無数のAIモデルが転がっていますが、「誰がGGUF形式に変換(量子化)したか」によって、AIの賢さや動作の安定性が全く異なります。
適当にダウンロードして「このAI、全然使えないな」と誤解しないよう、2026年現在の最新環境に合わせた「推奨リポジトリ」と「回避すべきリポジトリ」をまとめました。
👑 【推奨】今、フォローすべきリポジトリ
2025年〜2026年の最新モデル(Qwen 3.5, Llama 4, gpt-oss等)を、最高の精度で量子化しているグループです。
| リポジトリ名 | 特徴と推奨理由 |
| unsloth | 2026年のゴールド標準。 最新の「Dynamic 2.0」量子化やQAT(量子化適応学習)を適用しており、通常のGGUFより1〜2%精度が高い。Macでの動作報告も最も多い。 |
| bartowski | 最速のデプロイ。 新モデル公開から数時間で全ビット数のGGUFを公開する。imatrixを用いた高品質な量子化が徹底されており、ハズレがない。 |
| mradermacher | 職人気質のバリエーション。 非常に細かい量子化レベルを提供。「あと数百MB削ってメモリに収めたい」時に頼りになる。 |
| QuantFactory | 安定した品質。 最新のLlama 4やMistral系の公式に近い品質でGGUF化を行っている。 |
| maziyarpanahi | マニアックな名作選。 評価の高いファインチューン(微調整版)モデルをいち早くGGUF化してくれる。執筆特化モデル探しに有用。 |
⚠️ 【回避・注意】利用を控えるべきリポジトリ
かつては有名でしたが、現在の環境や最適化(Mac向け)に適合していないグループです。
| リポジトリ名 | 理由と懸念点 |
| TheBloke | 「レガシー(遺産)」扱い。 2024年前半までは王者でしたが、現在は更新が止まっており最新モデルが存在しません。 |
| LoneStriker | EXL2特化。 主にNVIDIA GPU用のフォーマットが主力。GGUFもありますが、llama.cpp(Mac)向けの最適化が甘いケースが見受けられます。 |
| 個人名のみの未検証リポジトリ | 品質のバラツキ。 重要度行列(imatrix)を使わずに単純に量子化されたモデルは、特に4-bit以下で知能が著しく低下します。 |
シニアエンジニアの「失敗しない」選び方
リポジトリ名だけでなく、ファイル名や説明文に以下のキーワードが含まれているかを必ずチェックしてください。
[SWELLリスト(チェックマーク)]
imatrix(Importance Matrix):量子化する際に「どのパラメータが重要か」を事前に計算している証拠です。これがあるモデルは、同じ4-bitでも賢さが全く違います。Dynamic/QAT:特にunslothが提供している最新技術です。量子化による劣化を学習で補填しているため、32GBメモリの限界を攻める「中量級〜重量級」モデルでは必須の条件と言えます。
ターミナルで完結!Hugging Faceから直接ダウンロードする手順
それでは、推奨リポジトリから実際にモデルをダウンロードしてみましょう。Mac miniにSSH接続した状態からスタートします。
今回は第3回で導入した超高速パッケージマネージャー uv の実行コマンド(uvx)を使い、Hugging Face公式のCLIツールを一時的に呼び出してダウンロードする最もモダンで安定した手法を使います。
Step 1: Hugging Faceで目的のモデル名とファイル名を取得する
まずは普段お使いのPCのブラウザでHugging Faceにアクセスし、上部の検索窓に目的のモデル名を入力しお目当てのレポジトリページを開きます。
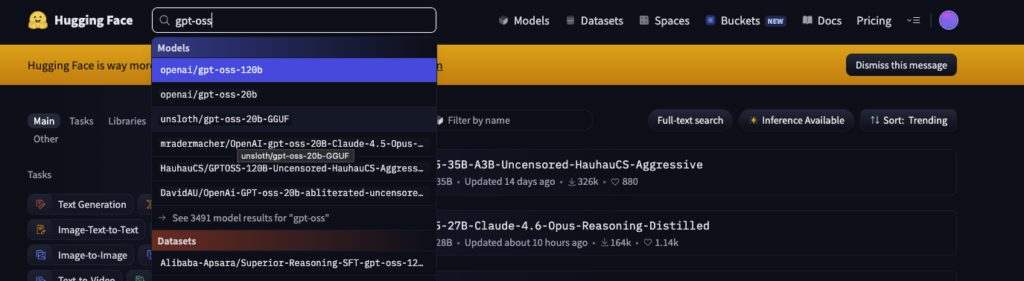
- ページ上部の「リポジトリ名(例:
unsloth/gpt-oss-20b-GGUF)」をコピーします。
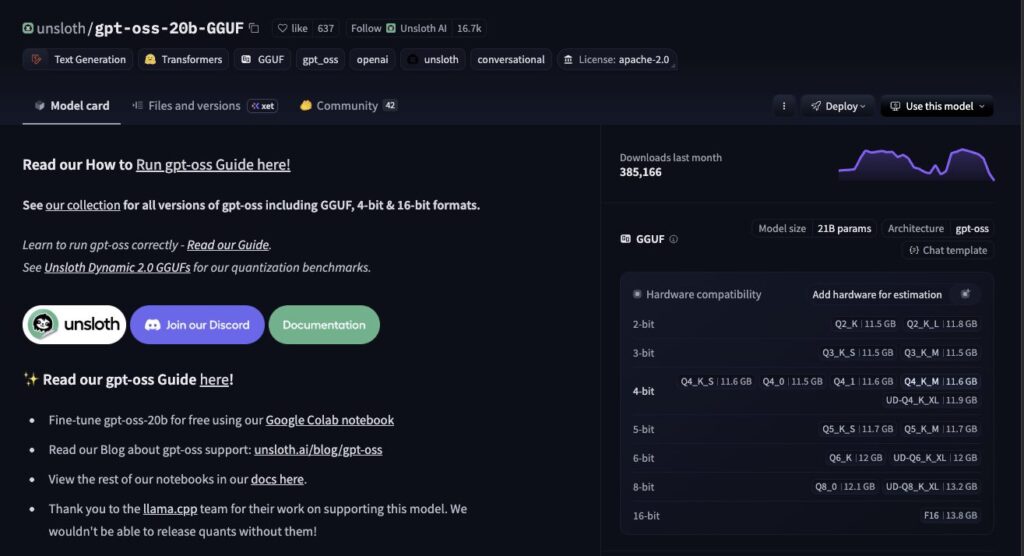
- 右のGGUF欄のダウンロードしたいモデル名(Q4_K_M)をクリックし、ダウンロードしたいGGUFファイル名
(例:gpt-oss-20b-Q4_K_M.gguf)をコピーします。
Step 2: uvx コマンドでMac miniへ直接ダウンロード
以下のコマンドをコピーし、先ほど取得した「リポジトリ名」と「ファイル名」を当てはめて実行します。
【実践:推奨リポジトリからのダウンロード例】
例えば、中量級の本命である gpt-oss-20b を、最も信頼できる unsloth から取得する際の最新コマンドは以下のようになります。
Bash
/Users/llm-admin/.local/bin/uvx --from "huggingface_hub[cli]" hf download \
unsloth/gpt-oss-20b-GGUF \
gpt-oss-20b-Q4_K_M.gguf \
--local-dir /Users/llm-admin/llm_base/models
[SWELLキャプションボックス(解説)]
Step 3: 【重要】新しいモデルを認識させる「再起動の儀式」
【初心者が一番ハマる落とし穴】
ダウンロードが100%になり、ファイルが /models フォルダに配置されても、Open WebUIの画面をリロードしただけでは新しいモデルは絶対に表示されません。
裏側で動いている推論エンジン(llama.cpp)は、起動した瞬間にフォルダ内の「目録」を作ってしまうため、後から追加されたファイルに気づけないのです。新しいモデルを追加した後は、必ず以下のコマンドで「エンジンの再起動(リロード)」を行ってください。
ターミナルで以下の1行コマンドを実行します。
Bash
# llama-server プロセスを安全に再起動して、新しいモデルを読み込ませる
sudo launchctl kickstart -k system/com.llm.llamacpp
(※ -k オプションは、「現在のプロセスを一度キル(終了)して、すぐに新しく立ち上げ直す」という安全な再起動の指示です)
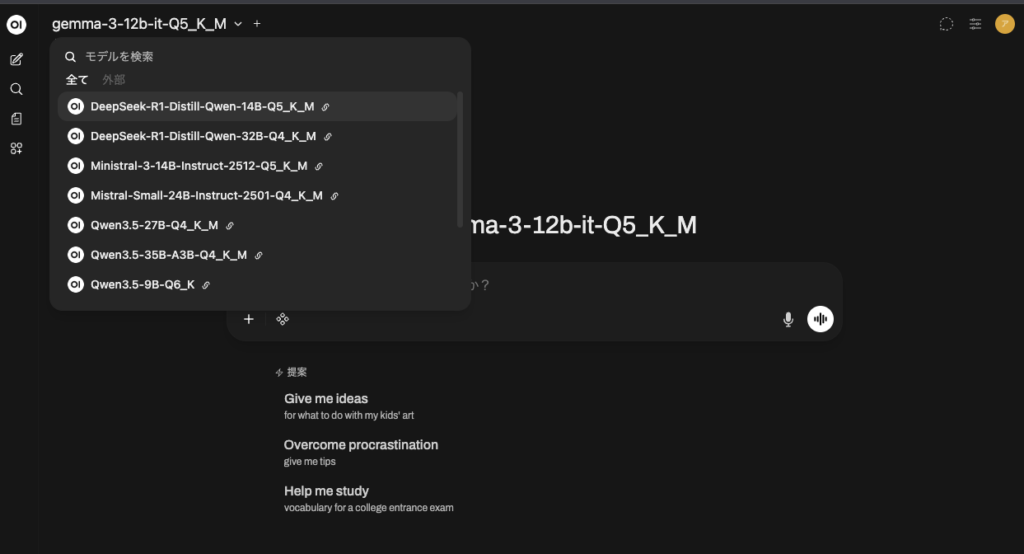
画面上部のモデル選択プルダウンに、今追加した「新しいモデル名」が無事に表示されているはずです!
上記のコマンドを実行後、30秒ほど待ちます(サーバーが再び目録を作り直し、GPU用RAMを確保しています)。
Open WebUIのチャット画面を開き、ブラウザをリロード(更新)します。
まとめと次のステップ
お疲れ様でした!これで、世界中の優秀なAIモデル(GGUF)を、最高品質の状態でMac miniへ直接お迎えできるようになりました。
まずは今回紹介した「unsloth」や「bartowski」のリポジトリをブックマークしておくことを強くお勧めします。
さて、賢いモデルを無事にダウンロードできたところで、いよいよAIの性能を試したくなりますよね。
ですがその前に!せっかくならこのAIに「最新のWebニュースや今日の天気」も答えられるようになってほしくないですか?
次回は急遽予定を変更し、このローカル環境に自前のRAG(Web検索機能)「SearXNG」を組み込む拡張編をお届けします。お楽しみに!
⭐️ ハブ記事

コメント